Distributed System 7-2
분산시스템 — Consistency and Replication Part 2 (클라이언트 중심 일관성 모델)
이 문서는 Tanenbaum의 Distributed Systems 7장(Consistency and Replication)을 기반으로 한 강의(슬라이드 22번부터 37번 부근까지)를 정리한 것이다. 다루는 범위는 클라이언트 중심 일관성 모델(client-centric consistency model)의 개요와 표기법에서 시작하여, 네 가지 모델 — 단조 읽기(monotonic reads), 단조 쓰기(monotonic writes), 자기 쓰기 읽기(read your writes), 읽은 뒤 쓰기(writes follow reads) — 을 각각의 정의·예제·그림(7-12 ~ 7-15)을 통해 살펴보는 데까지이다. 이 문서는 첫 번째 강의 정리본인
dsc_ch7_pt1.md의 내용을 잇지만, 그 자체로 완결되도록 작성하였다.
0. 지난 시간 복습
지난 시간에는 복제(replication)를 하는 이유(신뢰성·가용성·성능)와 그 대가인 일관성 비용을 살펴보고, 일관성과 성능의 트레이드오프 위에서 엄격한 일관성을 완화한 데이터 중심 일관성 모델(data-centric consistency model)을 다루었다. 지속적 일관성(continuous consistency)의 세 가지 불일치 축(수치·신선도·순서), 순서만 맞으면 되는 순차적 일관성(sequential consistency), 인과 관계가 있는 연산의 순서만 맞으면 되는 인과적 일관성(causal consistency)을 거쳐, 쓰기-쓰기 충돌이 드문 데이터 스토어에 적용하는 최종 일관성(eventual consistency)까지 보았다. 최종 일관성은 게으른 전파(lazy propagation)를 허용해 구현이 저렴하지만, 한 사용자가 짧은 시간에 서로 다른 레플리카를 이동하며 접근할 때(그림 7-11) 일관성이 깨질 수 있다는 한계가 있었다. 이 한계를 보완하는 것이 이번 시간에 다루는 클라이언트 중심 일관성 모델이다.
1. 클라이언트 중심 일관성 개요
클라이언트 중심 일관성(client-centric consistency) 모델이 데이터 중심 모델과 갖는 가장 큰 차이는, 일관성을 맞춰 주는 대상이 하나의 단일 클라이언트(single client)라는 점이다.
- 이 모델은 단 하나의 클라이언트(사용자)가 여러 개의 복제된 데이터 스토어 사이를 이동하며 데이터를 접근할 때, 그 접근의 일관성을 보장하는 데 초점을 맞춘다.
- 서로 다른 클라이언트(different client)들 사이의 동시 접근에 대해서는 아무런 보장도 하지 않는다. 다른 클라이언트는 관심사가 아니므로 데이터 중심 모델의 그림과 달리 등장하지 않는다.
- 뒤의 예제에서는 간단히 데이터 스토어가 두 개인 경우를 다룬다. 두 데이터 스토어에 같은 데이터 아이템
x가 복제되어 있고, 한 사용자가 한 스토어에서x를 접근한 뒤 위치를 옮겨 다른 스토어의 같은x를 접근하는 상황이다.
연산 조합으로 나뉘는 네 가지 모델 (★ 핵심)
클라이언트가 한 데이터 스토어에서 데이터 아이템에 수행할 수 있는 연산은 읽기(read)와 쓰기(write) 두 가지이다. 첫 번째 스토어에서 한 연산과, 이동 후 두 번째 스토어에서 한 연산의 조합에 따라 네 가지 모델이 나온다.
| 첫 연산 | 둘째 연산 | 모델 이름 |
|---|---|---|
| Read | Read | 단조 읽기 (Monotonic Reads) |
| Write | Write | 단조 쓰기 (Monotonic Writes) |
| Write | Read | 자기 쓰기 읽기 (Read Your Writes) |
| Read | Write | 읽은 뒤 쓰기 (Writes Follow Reads) |
네 모델은 결국 모두 같은 이야기를 한다. “이전 데이터 스토어에서 수행한 연산의 내용이 다른 데이터 스토어에 반영(propagation)되고 난 다음에 다음 연산을 수행하는가.” 조건은 동일하고, 단지 그 두 연산이 읽기인지 쓰기인지의 조합만 다르다.
2. 표기법(Notation)
네 모델의 그림 예제를 이해하려면 표기법을 먼저 알아야 한다. 데이터 중심 모델의 표기(Wᵢ(x)a)와는 다른, 클라이언트 중심 전용 표기이다.
xᵢ[t]— 시간t에i번째 데이터 스토리지(local copyLᵢ)에 있는 데이터 아이템x의 값이다. 여기서 아래 첨자i는 데이터 스토리지를 가리키는 인덱스이고,t는 시간이다. (뒤 예제에서는t가 생략되어xᵢ로만 표기되는 경우가 많다. 그러면 “i번 스토리지에 있는x“로 읽으면 된다.) 이 값은x가Lᵢ에서 초기화된 이후 수행된 일련의 쓰기 연산의 결과이다.WS(xᵢ[t])— 여기서S는 집합(set),W는 쓰기(write)이다. 즉 쓰기 집합(write set)으로, 시간t에Lᵢ의x값을 만들어 낸 일련의 쓰기 연산들의 집합이다.WS(xᵢ[t₁]; xⱼ[t₂])— 같은 데이터 아이템x인데 왼쪽은i번 스토리지, 오른쪽은j번(다른) 스토리지를 가리킨다. 이 표기는i번 스토리지의x에 시간t₁까지 수행된 쓰기 연산들이, 나중에 시간t₂에j번 스토리지에도 적용(전파)되었음을 나타낸다. 곧j번 스토리지의x(시간t₂)에는i번 스토리지에서 그 앞선 시간t₁에 갱신된 내용이 반영되어 있다는 뜻이다.
복제된 데이터는 한쪽이 갱신되면 일관성을 위해 그 내용을 다른 레플리카로 전파한다는 사실을 기억하면, 세 번째 표기는 “한 스토리지의 갱신이 다른 스토리지로 전파되어 반영된 상태”를 적은 것임을 알 수 있다. 이 세 번째 표기가 그림에서 “이전 연산이 다른 스토리지에 반영되었는가”를 가르는 핵심 표시가 된다.
3. 단조 읽기 (Monotonic Reads) (★ 핵심)
개념
클라이언트가 i번 스토리지의 x에 읽기를 수행하고, 이동하여 j번 스토리지의 (복제된) x에 또 읽기를 수행할 때 만족할 수 있는 모델이다.
- 정의: “한 프로세스가 데이터 아이템
x의 값을 읽으면, 그 프로세스가x에 대해 이어서 수행하는 모든 읽기는 항상 같은 값이거나 더 최신의 값을 반환한다.” - 즉 어떤 시간
t에x의 값을 본 프로세스는, 이후에 결코 그보다 오래된(older) 버전의x를 보지 않는다. - 얼핏 당연해 보이지만, 단조 읽기가 보장되지 않는 경우가 실제로 있을 수 있다.
예제 — 분산 이메일 데이터베이스
- 각 사용자의 메일박스가 여러 데이터 스토리지에 분산·복제되어 있고, 갱신(새 메일 도착 등)은 게으른 방식(on demand)으로 전파된다.
- 게으른 전파란, 한 스토리지가 갱신되었을 때 곧바로 다른 레플리카에 푸시(push)하는 것이 아니라, 나중에 다른 쪽에서 그 아이템을 접근하려 할 때 비로소 다른 스토리지에 갱신 여부를 확인받아 전파·적용하는 방식이다.
- 시나리오: 사용자가 샌프란시스코에서 메일을 읽는다(읽기만 하면 메일박스에 영향이 없다고 가정). 이후 뉴욕으로 날아가 메일박스를 다시 연다.
- 단조 읽기가 보장되면: 뉴욕에서 여는 메일박스에는 적어도 샌프란시스코에서 보았던 메일 내용이 모두 들어 있고, 그 이후 도착한 새 메일이 추가로 있을 수 있다.
- 보장되지 않으면: 샌프란시스코에서 도착한 새 메일이 아직 뉴욕까지 전파되지 않은 상태에서 뉴욕 스토리지를 읽으면, 샌프란시스코에서 보던 내용을 뉴욕에서 못 볼 수 있다. 더 오래된 데이터를 읽게 되어 단조 읽기 조건에 어긋난다.
그림 7-12 — 정수 예제로 검산

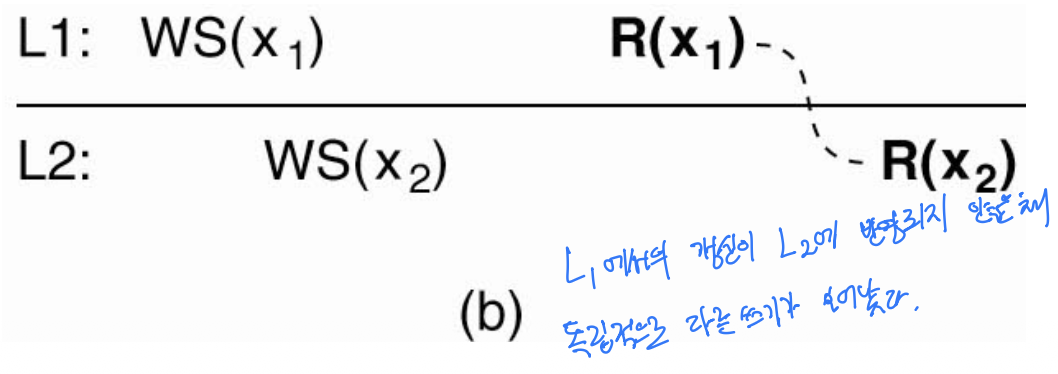
L1, L2는 데이터 스토리지 1번·2번이고 가로축은 시간이다. 굵은 글씨(boldface)로 표시되고 점선으로 연결된 연산이 같은 클라이언트가 순서대로 수행한 연산(L1에서 한 뒤 이동해 L2에서 수행)이다. 이해를 위해 x를 정수 변수로 보고 초깃값을 0이라 하자.
- (a) 단조 읽기를 보장하는 경우: 클라이언트가 L1에서
R(x₁)로x를 읽는다(그 앞에WS(x₁)이 있어 L1의 현재x값을 만들었다). 이동 후 L2에서x를 읽기 전에WS(x₁; x₂)가 있다 — 즉 L1에서 수행된 쓰기들이 L2에도 적용되었다. 따라서 L2에서 읽는 값은 L1에서 본 값과 같거나 더 최신이다. 조건 만족.- 예: L1의 쓰기가
x++(0→1)였다면, 그것이 L2에도 반영된 뒤 읽으므로 L2에서도 최소1을 읽는다.
- 예: L1의 쓰기가
- (b) 단조 읽기를 보장하지 않는 경우: L2에서 읽기 전에 있는 것은
WS(x₂)뿐이다. 이는 L1에서의 갱신이 L2에 반영되지 않은 채, L2에서 독립적으로 다른 쓰기가 일어났음을 뜻한다.- 예: 초깃값 0에서 L1의 쓰기는
x++(→ L1에서x=1), 그러나 이x++가 L2로 전파되지 않은 상태에서 L2에서는 따로x--가 수행되었다고 하자. (이x--는 읽기만 하는 우리 클라이언트가 아니라 다른 프로세스가 L2에 가한 독립적 갱신이다.) 그러면 L2의x는-1이 되고, 클라이언트는 L1에서1을 읽었다가 L2에서-1을 읽는다. 더 오래된(작은) 값을 읽었으므로 단조 읽기 위반이다. - 만약 L1의
x++가 L2에 먼저 반영(0→1)된 뒤 L2에서x--가 일어났다면 결과는0이 되어, 이전 쓰기가 포함된 위에 추가 갱신까지 더해진 “같거나 더 최신” 값이 되어 조건을 만족했을 것이다.
- 예: 초깃값 0에서 L1의 쓰기는
4. 단조 쓰기 (Monotonic Writes) (★ 핵심)
개념
클라이언트가 i번 스토리지에서 쓰기를 수행하고, 이동하여 j번 스토리지에서 또 쓰기를 수행하는 경우의 모델이다.
- 정의: “한 프로세스가 데이터 아이템
x에 수행하는 쓰기 연산은, 그 프로세스가x에 이어서 수행하는 어떤 쓰기 연산보다 먼저 완료(complete)된다.” - 쓰기를 “완료한다”는 것은, 이어지는 연산이 수행되는 사본이 같은 프로세스의 이전 쓰기 효과를 반영하고 있다는 뜻이다. 즉 다른 스토리지에서 다음 쓰기를 하기 전에, 그 스토리지에 이전 쓰기 내용이 먼저 반영되어 있어야 한다.
데이터 중심 FIFO 일관성과의 비교
| 구분 | 데이터 중심 FIFO 일관성 | 단조 쓰기(client-centric) |
|---|---|---|
| 대상 | 모든 클라이언트(프로세스) | 단일 프로세스 |
| 공통점 | 같은 프로세스의 쓰기 연산이 모든 곳(everywhere)에서 올바른(같은) 순서로 수행됨 | 좌동 |
- FIFO(First-In First-Out) 일관성은 한 프로세스가 수행한 쓰기들이 모든 데이터 스토리지에서, 그리고 모든 사용자에 대해 같은 순서로 적용되는 것이다.
- 단조 쓰기도 “이전 쓰기가 모두 적용된 뒤 다음 쓰기가 적용된다”는 순서 제약을 가진다는 점에서 FIFO와 유사하다. 차이는 단조 쓰기가 이 순서 제약을 하나의 단일 프로세스에 대해서만 적용한다는 점이다.
예제 — 소프트웨어 라이브러리
x를 어떤 소프트웨어 라이브러리라 하고, 그것이 다른 스토리지에도 복제되어 주기적으로 갱신된다고 하자.- 단조 쓰기가 보장되는 데이터 스토어에서 한 스토리지의 라이브러리가 갱신되면, 그것은 이전 갱신들이 이미 모두 반영된 상태에서 이번 갱신이 일어남을 보장한다. 모든 스토리지에서 갱신 순서가 지켜진다.
그림 7-13 — 정수 예제로 검산
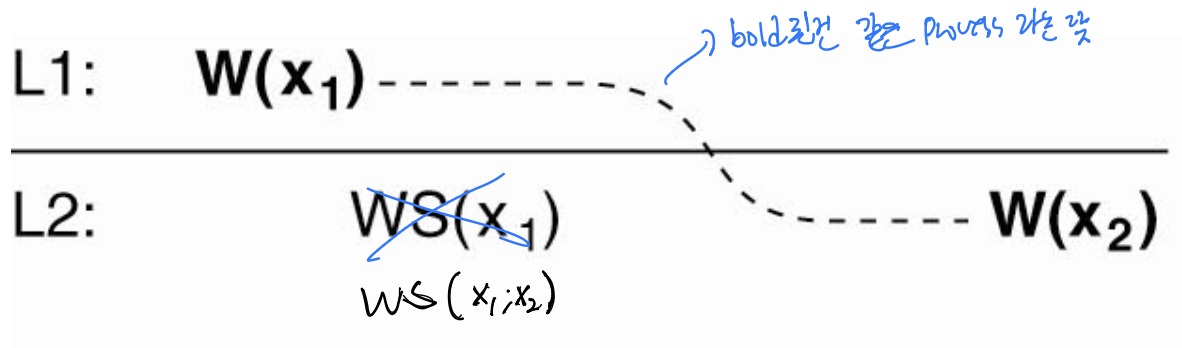

x를 정수, 초깃값 0(L1, L2 모두 0)으로 두고, 각 쓰기를 x++로 가정한다.
- (a) 단조 쓰기를 만족하는 경우: L1에서
x++로x가1이 된다. 이동 후 L2에서 두 번째x++를 하기 전에WS(x₁; x₂)가 있다 — L1의x++가 L2에도 반영되어 L2의x도1이 된 상태이다. 그 위에서x++를 하니 결과는2. 이전 쓰기가 반영된 뒤 다음 쓰기가 적용되었으므로 조건 만족. - (b) 단조 쓰기를 만족하지 않는 경우: L2에서의 쓰기 앞에
WS(L1→L2 반영 표시)가 없다. 즉 L1의x++가 L2에 반영되지 않았다. 그러면 L2의x는 여전히0이고, 거기서x++를 하면 결과는2가 아니라1이 된다. 이전 쓰기가 반영되지 않은 채 새 쓰기를 해 버렸으므로 단조 쓰기 위반이다.
핵심 대비: 두 번째 쓰기 앞에
WS(x₁; x₂)(이전 쓰기의 전파 반영)가 있으면0→1→2로 누적되어 만족, 없으면0→1에 그쳐 위반이다.
5. 자기 쓰기 읽기 (Read Your Writes) (★ 핵심)
개념
세 번째 모델은 클라이언트가 먼저 쓰기를 수행하고, 이동하여 다른 스토리지에서 같은 x를 읽는 경우이다.
- 정의: “한 프로세스가 데이터 아이템
x에 수행한 쓰기 연산의 효과는, 그 프로세스가x에 이어서 수행하는 읽기 연산에 항상(always) 보인다.” - 즉 내가 한 쓰기는 어느 스토리지에서 읽든 그 읽기 전에 항상 완료(반영)되어 있어, 내가 방금 쓴 내용을 읽을 수 있다.
- 같은 스토리지에서 쓰고 바로 읽으면 자명하므로 고민할 필요가 없다. 문제는 복제된 환경에서 이동했는데 갱신이 아직 반영되지 않아, 새 값이 아닌 오래된(old) 값을 읽게 되는 경우이다.
예제 — 웹 문서 캐시와 비밀번호 변경
| 예제 | 내용 |
|---|---|
| 웹 문서 갱신 | 웹 페이지를 갱신했는데, 브라우저나 서버가 캐시된 이전 사본을 반환하면 사용자는 자신이 갱신한 내용을 보지 못한다. 자기 쓰기 읽기 위반. |
| 비밀번호 변경 | 디지털 라이브러리가 여러 스토리지로 복제·관리되고, 비밀번호를 전담하는 별도 서버가 있다. 한 스토리지에서 비밀번호를 바꾸면 그 내용이 다른 레플리카에 전파되는 데 시간이 걸린다. 아직 전파되지 않은 스토리지에 로그인하려 하면 잠시 접근하지 못할 수 있다. |
그림 7-14 — 정수 예제로 검산

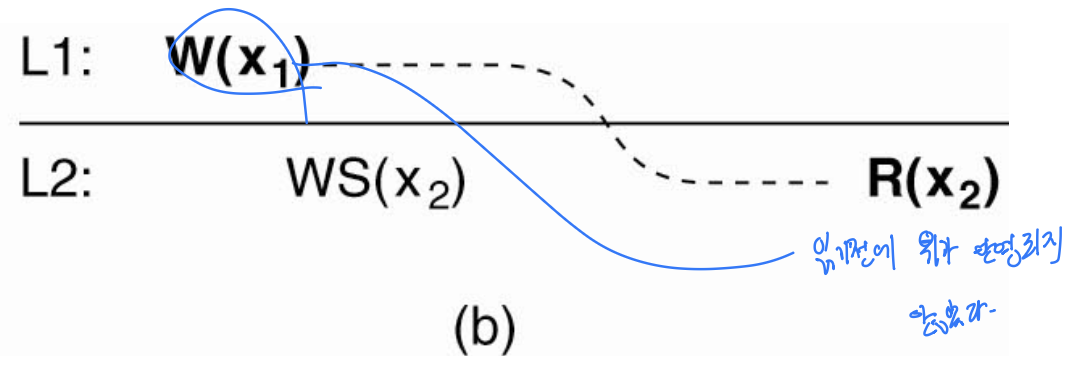
x를 정수, 초깃값 0으로 두고 쓰기를 x++로 가정한다.
- (a) 자기 쓰기 읽기를 만족하는 경우: L1에서
x++로x가1이 된다. 이동 후 L2에서x를 읽기 전에WS(x₁; x₂)가 있다 — L1의 쓰기가 L2에 반영되어 L2의x도0→1이 되었다. 따라서 L2에서 읽으면 갱신된1을 읽는다. 내가 쓴 내용이 그대로 읽혔으므로 조건 만족. - (b) 만족하지 않는 경우: L2에서 읽기 전의
WS에 L1에서의x++가 반영되어 있지 않다(L2에는 독립적 쓰기만 있거나 아무것도 없음). 다른 쓰기가 없었다고 하면 L2의x는 여전히0이고, 읽으면0을 읽는다. 방금 증가시킨 값이 반영되지 않아 오래된 값을 읽었으므로 자기 쓰기 읽기 위반이다.
그림 7-12(a)와 매우 비슷하지만, 여기서는 일관성을 결정하는 기준이 프로세스의 마지막 읽기가 아니라 마지막 쓰기라는 점이 다르다.
6. 읽은 뒤 쓰기 (Writes Follow Reads) (★ 핵심)
개념
네 번째 모델은 클라이언트가 먼저 읽기를 수행하고, 이동하여 다른 스토리지에서 같은 x에 쓰기를 수행하는 경우이다.
- 정의: “한 프로세스가
x를 읽은 뒤 같은x에 수행하는 쓰기 연산은, 그 프로세스가 읽었던 값과 같거나 더 최신인x의 값 위에서 수행됨이 보장된다.” - 즉 이어지는 쓰기는 그 프로세스가 가장 최근에 읽은(most recently read) 값을 반영한, 최신 상태의
x사본 위에서 수행된다. - 이 모델은 갱신이 이전 읽기 연산의 결과로서 전파되도록 보장한다.
예제 — 네트워크 뉴스그룹의 답글
- 요즘으로 치면 SNS와 비슷하다. 사용자가 먼저 글(article)
A를 읽고(read), 그에 대한 답글(reaction)B를 단다(write). - 읽은 뒤 쓰기가 보장되면, 답글
B는 원본 글A가 이미 반영된 사본 위에만 쓰인다. 즉 내가 답글을 쓰는 사본에는 내가 읽었던 원본이 반드시 먼저 들어가 있어, 그 사본을 어디서 읽든 항상 “원본A→ 반응B” 순서가 지켜진다. (이 성질은 단일 클라이언트의 읽기→쓰기 인과를 지키는 것이지만, 결과적으로 그 사본을 보는 다른 독자에게도 원본을 본 뒤에야 반응을 보도록 일관된 순서를 보장하게 된다.)
그림 7-15 — 정수 예제로 검산
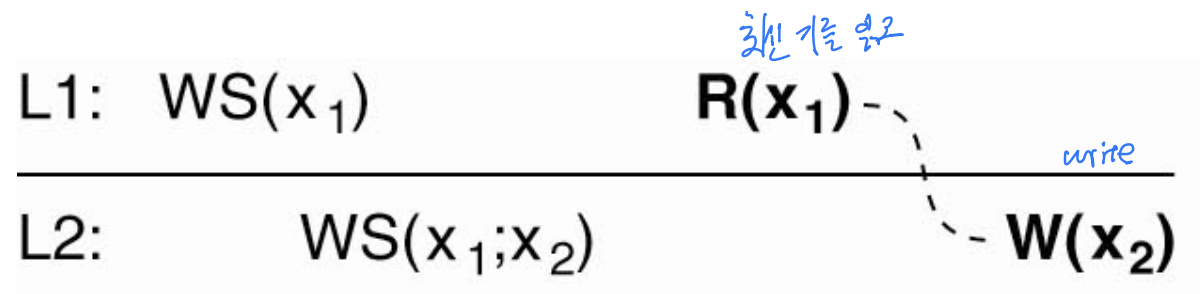

x를 정수, 초깃값 0으로 두자. 사전에 L1에서 x++(0→1)가 수행되어 L1의 x는 1인 상태이다.
- (a) 읽은 뒤 쓰기를 만족하는 경우: 프로세스가 L1에서
x를 읽어1을 얻는다. 이동 후 L2에서x++를 하기 전에WS(x₁; x₂)가 있다 — L1에서 수행된 쓰기가 L2에도 반영되어 L2의x도 이미1이 되었다. 그 위에서x++를 하니1→2. 읽었던 값(1) 이상의 최신 값 위에서 쓰기가 일어났으므로 조건 만족. - (b) 만족하지 않는 경우: L2에서의 쓰기 앞에
WS(L1→L2 반영 표시)가 빠져 있다. L1의x++가 L2에 반영되지 않았고, L2에서 독립적 쓰기도 없었다고 하면 L2의x는 여전히0이다. 거기서x++를 하면 결과는2가 아니라1이 된다.- 투명성(transparency) 관점에서 보면 클라이언트는 방금
1을 읽고 하나 증가시켰으니2가 되리라 기대한다. 그러나 실제로는1이 나오는 황당한 상황이 된다. 내가 읽은 값을 만든 쓰기가 다음 쓰기 위치에 반영되지 않은 채 갱신했기 때문이며, 따라서 읽은 뒤 쓰기 위반이다.
- 투명성(transparency) 관점에서 보면 클라이언트는 방금
네 모델 한눈에 정리
| 모델 | 연산 순서 | 보장하는 것 | 그림 |
|---|---|---|---|
| 단조 읽기 (Monotonic Reads) | Read → Read | 한 번 읽은 값보다 오래된 값을 다시 읽지 않음 | 7-12 |
| 단조 쓰기 (Monotonic Writes) | Write → Write | 이전 쓰기가 완료된 뒤 다음 쓰기가 수행됨 | 7-13 |
| 자기 쓰기 읽기 (Read Your Writes) | Write → Read | 내가 쓴 내용이 이후 읽기에 항상 보임 | 7-14 |
| 읽은 뒤 쓰기 (Writes Follow Reads) | Read → Write | 읽은 값(이상의 최신 값) 위에서 쓰기가 수행됨 | 7-15 |
네 모델은 모두 “이전에 수행한 연산의 결과가 다른 모든 스토리지에 반영된 뒤에 다음 연산이 수행되는가”라는 동일한 조건을, 연산의 조합만 바꿔 본 것이다. 또한 클라이언트 중심 모델은 데이터 중심 모델보다 제약(다른 클라이언트는 신경 쓰지 않고 단일 프로세스만 고려)이 가벼워, 상대적으로 구현하기 쉽다는 점도 기억할 만하다.
다음 시간 예고
여기까지가 일관성 모델(데이터 중심 + 클라이언트 중심)이다. 다음 차시부터는 7장의 뒷부분인 복제 관리(replication management), 곧 복제 자체를 어떻게 수행하는가를 다룬다(슬라이드 38번 이후). 주요 주제는 다음과 같다.
- 복제 서버 배치(replica-server placement) — 어디에 서버를 둘 것인가.
- 콘텐츠 복제와 배치(content replication and placement) — 영구(permanent)·서버 주도(server-initiated)·클라이언트 주도(client-initiated) 세 종류의 레플리카.
- 콘텐츠 분산(content distribution) — 무엇을 전파할 것인가(상태 vs 연산, invalidation), 갱신을 끌어올지 밀어낼지(pull vs push), 리스(lease) 기반 하이브리드, 유니캐스트 vs 멀티캐스트.
한눈에 보는 전체 구조
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
7장 Consistency and Replication (Part 2: 슬라이드 22~37)
│
├─ 0. 복습 — data-centric 모델 + eventual의 한계(그림 7-11)
│
├─ 1. 클라이언트 중심 일관성 개요
│ ├─ 대상 = 단일 클라이언트 (다른 클라이언트는 무관)
│ ├─ 데이터 스토어 2개 사이 이동
│ └─ 연산 조합(R/W × R/W) → 네 가지 모델
│
├─ 2. 표기법(notation)
│ ├─ xᵢ[t] — i번 스토리지의 x 값(시간 t)
│ ├─ WS(xᵢ[t]) — 그 값을 만든 쓰기 집합(write set)
│ └─ WS(xᵢ[t₁]; xⱼ[t₂]) — i의 쓰기가 j로 전파·반영됨 ← 핵심 표시
│
├─ 3. 단조 읽기 (Monotonic Reads) ★ R→R
│ ├─ 정의: 더 오래된 값을 다시 읽지 않음
│ ├─ 예: 이메일 SF→NY
│ └─ 7-12 (a) 반영 後 read=만족 / (b) 미반영=위반 (1 vs -1)
│
├─ 4. 단조 쓰기 (Monotonic Writes) ★ W→W
│ ├─ 정의: 이전 write 완료 後 다음 write
│ ├─ FIFO(전 클라이언트) vs 단조쓰기(단일 프로세스)
│ ├─ 예: 소프트웨어 라이브러리
│ └─ 7-13 (a) 0→1→2=만족 / (b) 0→1=위반
│
├─ 5. 자기 쓰기 읽기 (Read Your Writes) ★ W→R
│ ├─ 정의: 내 write가 이후 read에 항상 보임
│ ├─ 예: 웹문서 캐시 / 비밀번호 변경
│ └─ 7-14 (a) read=1 만족 / (b) read=0 위반
│
└─ 6. 읽은 뒤 쓰기 (Writes Follow Reads) ★ R→W
├─ 정의: 읽은 값(이상) 위에서 write 수행
├─ 예: 뉴스그룹/SNS 답글
└─ 7-15 (a) 1→2 만족 / (b) 0→1 위반(기대 2)
(→ 복제 관리는 다음 차시)