Distributed System 2
Architecture
분산 시스템 설계시 server, client 내부를 어떻게 구성해야 할까?
Goal of distributed systems
- 아래의 platform은 heterogeneous 할텐데 이를 middleware가 잘 숨겨줄수 있어야해
- Distribution transparency를 제공
- Adaptability 제공(상황에 따라 변화할수 있으면 좋을 거야)
Architecture Styles
Software architecture은 sw component들로 구성되어있다. Architecture style의 경우 요소들에 의해 나뉘어진다.
- component들 끼지 어떻게 연결되어 있는가?
- component간 data를 어떻게 주고 받는가
- 이런 element들이 시스템에 jointly configured 되어있는가?
용어 정리
- Component: A modular unit with well defined required and provided interfaces that is replaceable within its environment(component의 장점으로 볼수 있어)
- Connector: mechanism that mediates communication, coordination, or cooperation among components
Architecture style의 종류들
- Layered architectures
- Object-based architectures
- Data-centered architectures
- Event-based architectures
Distributed system의 Goal을 잘 이룰수 있게 해야하지만 trade off도 잘 고려하렴
Layered Architecture
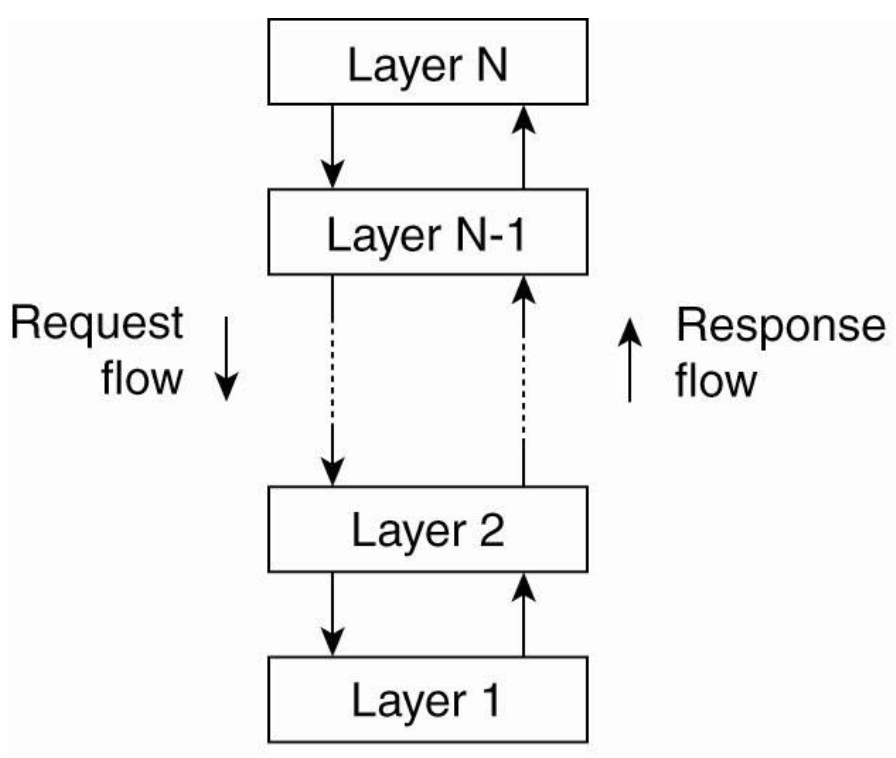
- 인접해 있는 layer들 끼리만 통신할수 있어야해
- Network쪽에서 많이 쓰인다.
- Interface를 정의해서 지킨다면 바뀌는 layer만 넣다 뻈다 할수 있어 -> maintanence가 쉬워져
Object-based architecture
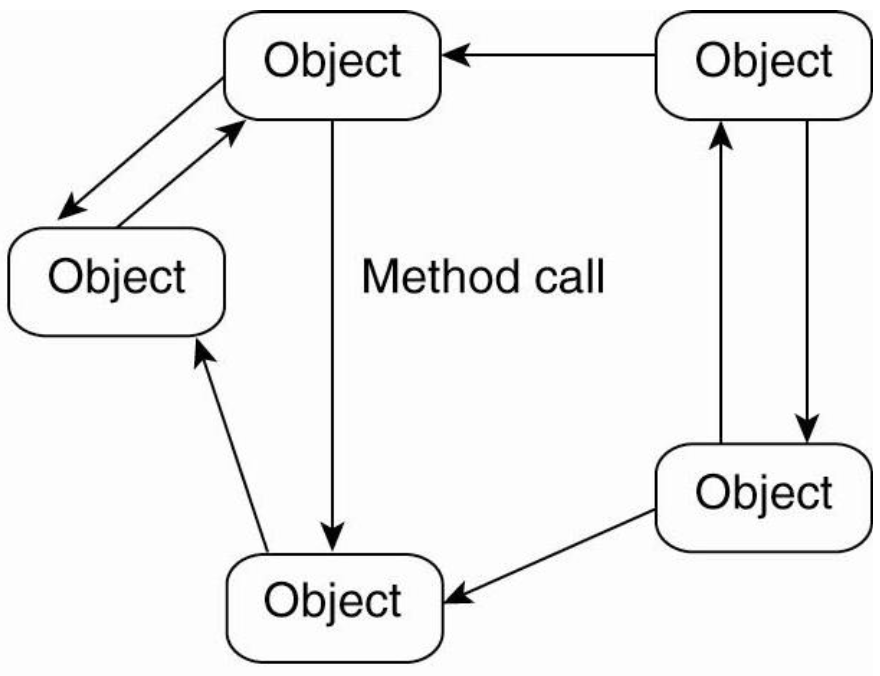
- Layered architecture에서 지켜야하는 규율이 느슨해진것
- Component들 끼리 RPC로 연결되어 있어
- Component들이 같은 machine에 있을수도 있고 다른 machine에서 돌아가고 있을수도 있다.
Data-centered architectures
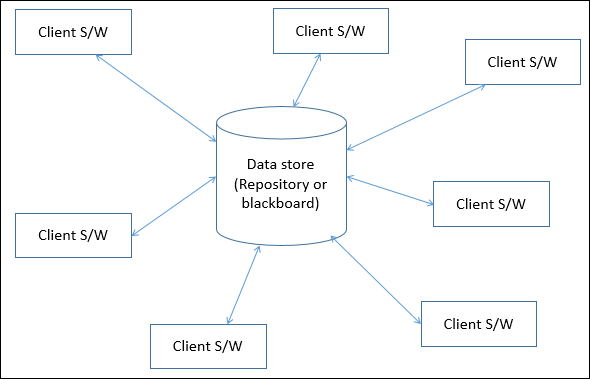
- 공통 (passice or active) repository에서 process들이 communicate한다고 볼수 있어
- 중앙 repo에 모든 data를 저장해 두기 때문에 다른 component가 죽어있어도 repo에서 data를 꺼내 쓸수 있어
- e.g. web server와 web browser의 관계
Event-based architecture
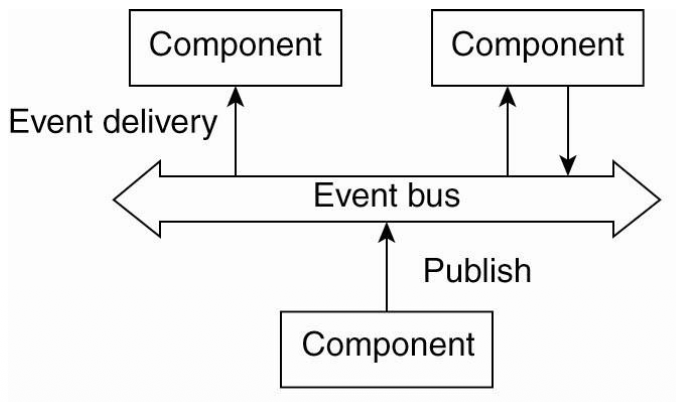
- Processes essentially communicate through the propagation of events, which optionally also carry data
- Pub/Sub system
- Process are loosely coupled (장점)
- e.g. IOT system에서 자주 쓰임
Event-based + Data-centered architectures
- Shared data spaces
- 원래 event based에서는 component가 죽어있으면, 해당 component는 그 데이터를 받을 방법이 아예없었는데 이제 decoupled in time 가능함
System architecture를 구분 할수 있는 다른 관점
How many distributed systems are actually organized by considering where sw components are placed
- Centralized architectures (Server-Client)
- Decentralized architectures (P2P)
- Hybrid architectures
Centralized architecture
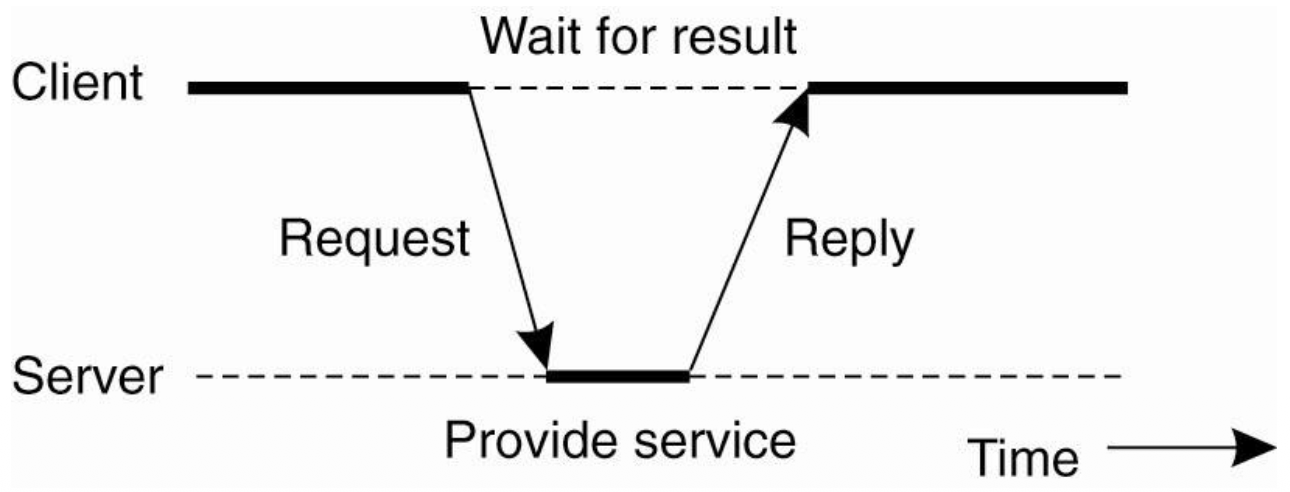
- Client-Server model: reply-request의 반복으로 이어나간다. Implemented by protocol
Protocol 종류에 따른 차이
Connectionless Protocol
- 장점: Efficient해
- 단점: Not reliable하고 이를 application이 not reliable 한거를 관리해줘야해
- 그냥 unreliable해서 lost되는 경우 그냥 다시 보내면 되는거 아닌가 할수 있는데 idempotent한 경우는 그렇게 하지 못해
- e.g. UDP 따라서 주로 LAN에서 쓰임
Idempotent: 반복해서 Operation을 실행해도 되는 경우
- e.g. “이 계좌에 1000불 보내줘” 요청에 대한 응답이 lost된 경우, 해당 요청을 다시 보낼수 없어 <- Not idempotent한 경우
Connection-Oriented Protocol
- Client가 service를 request하면 protocol이 우선 sets up a connection to server
- 장점: 안정적
- 단점: relatively costly
- e.g. TCP 따라서 주로 WAN에서 쓰임
Main issue in Centralized architectures
특정 component들을 Client에 둘까 Server에 둘까?
component가 3가지 종류로 나뉘는데 이것들을 어디에 두느냐에 따라 전체적인 system 구성이 달라진다.
- The user-interface level: input/output을 담당, 주로 client에 구성되는 것이 알반적, 현대에 와서 UI말고도 data를 가공하는 등 많은 role이 추가되었다.
- The processing level: sw의 core 파트, application 종류에 따라 구현, workload가 아주 vary 하다. (Not many common aspect)
- The data level: 실제 데이터를 관리하고 저장하고 있어, datas are often persistent, 보통 server side에 implementation
예시
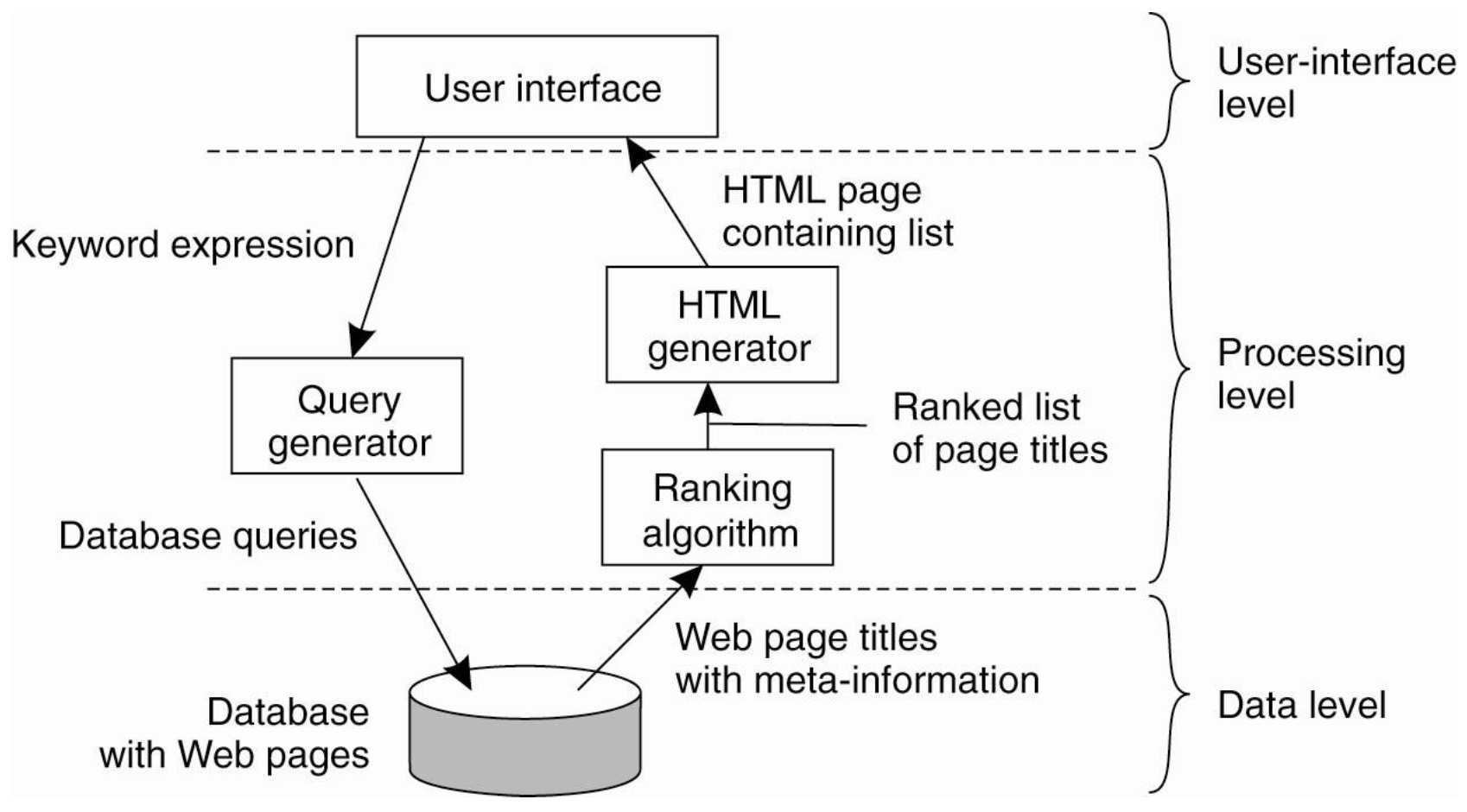
다음과 같이 구성하는 아주 많은 방법이 있어
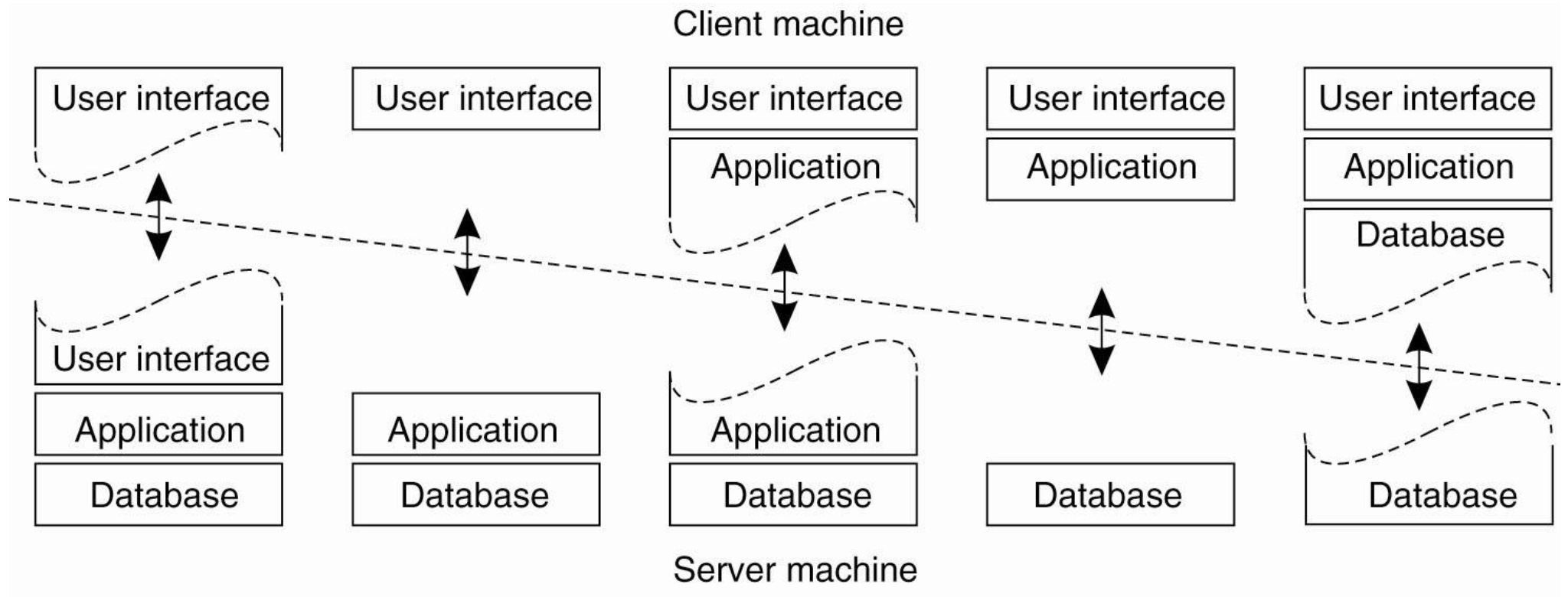
Single server이 multiple server running on different machines로 replace되는 경우가 많아서 server side solutions도 분산되고 있어. 이에 따라 Server도 sometimes act as a client.
Decentralized architecture (Peer to Peer system)
용어 정리
- Vertical Distribution: logically different한 component들을 여러 machine에 두는 것
- Horizontal Distribution: logically equivalent한 component들이 여러 machine에 있어 (Peer to Peer systems)
장점: Single point failure 해결, 확장성으로부터 자유로워
고려해야할 사항
- 각각의 process가 둘다 client, server로 둘다 행동할거야
- Peer간의 oraganization을 overlay network내에서 어떻게 배치할지가 큰 question (Channel간의 논리적 connection)
- 랜럼하게 아무 peer들 간의 communication이 자유롭지 않아.
Types of p2p
- Structured P2P: 규칙에 따라 peer들을 연결하겠다.
- Unstructured P2P: 단순하게 random혹은 모든 peer들을 다 연결하겠다.
Structured P2P
Overlay Network가 deterministic procedure로 구성되어 있다.
- Process를 정리하기 위해 **Distributed Hash Table(DHT)를 쓴다.
- 띠라서 process를 lookup, 관리하는데는 시간이 얼마 들지 않아
- 사용자가 data를 요청하면 해당 데이터를 들고 있는 node의 network address를 return해 (완전 p2p는 불가, 어느정도 서버가 존재한다.)
- e.g. Chord: 이건 따로 예시보고 정리하면 좋을듯
Unstructured P2P
- Overlay network를 구성하는데 randomized algorithm에 rely 한다.
- 각 노드가 list of neighbors를 가지고 있어
- 특정 데이터 아이템의 위치를 찾을때 broadcast를 해야해서 floods the network with a search query
Membership Management: 각 node들의 neighbor들을 어떻게 관리할까?
- 각 노드들은 각자 c neighbors들에 대한 정보를 가지고 있어(partial view)
- Neighbor에 대한 정보도 random하게 list가 update 돼
- 이렇게 해도 최초 연결할때는 neighbor의 정보를 알아야 해서 broadcast를 해야, 원하는 데이터의 위치를 deterministic하게 찾을 수 없어
Superpeers
=> 이런식으로 unstructured p2p하면 계속 broadcasting이 일어날거고 데이터를 deterministic하게 찾을수 없어
이를 해결하기 위해 superpeer를 도입했다.
- superpeers(broker의 역할): 모르는게 있으면 superpeer한테 물어보세요 -> overlay 구축하기도 편해졌어
새로운 문제
- 누가 superuser가 되면 좋을까(네트워크에 오래 머물고 HA를 가지는 유저가 되면 좋겠지)
- 처음 네트워크에 들어온 노드에 어떤 superpeer를 붙일까? (물리적으로 distance가 적은 superpeers가 언제나 좋은건 아니야)
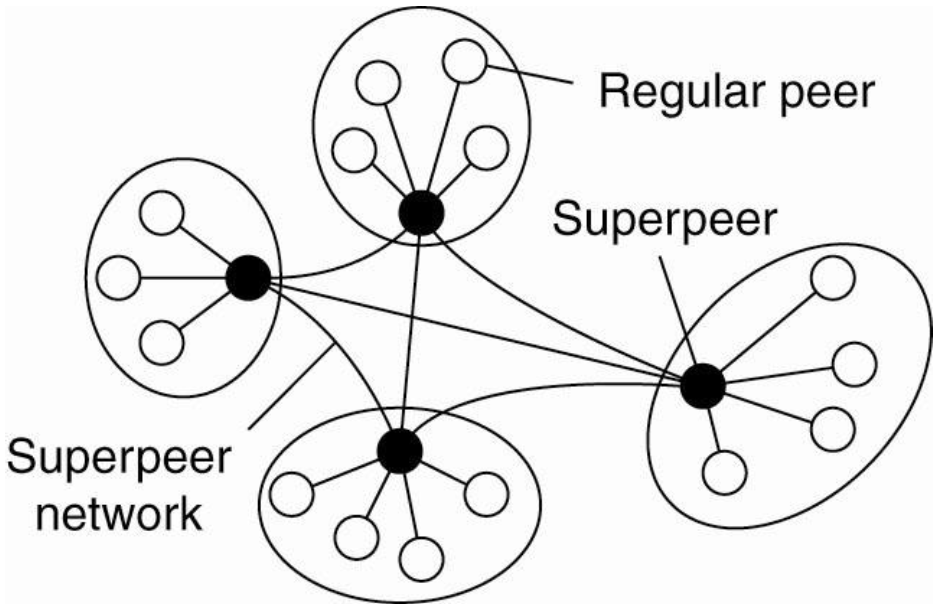 hierarchical organization (similar to 다중서버를 갖는 client-server 구조)
hierarchical organization (similar to 다중서버를 갖는 client-server 구조)
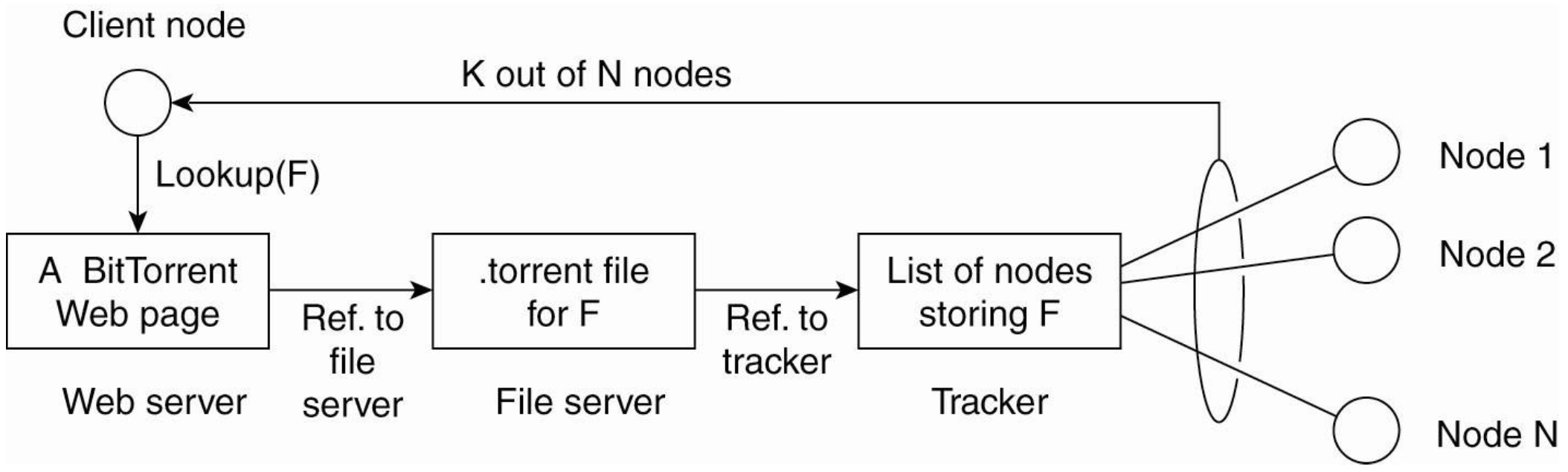
Hybrid Architecture
- Client-server solutions combined with decentralized architectures
- Edge-server systems
- Collaborative distributed systems
- Peer간의 통신 전에 server를 한번 거치게 돼
- e.g. BitTorrent(tit for tat) p2p이지만 tracker(이 파일을 가지고 있는 active 노드를 가지고 있는 서버)라는 서버를 두고 있다.
Architectures vs Middleware
Middleware systems는 specific architectural style을 따라
- Designing applications may become simpler
- 하지만 시간이 지나면 사용자가 원래 구상했던것과 많이 달라져서 더이상 해당 middleware가 optimal하지 않아질수 있아.
=> 이런 문제를 해결하기 위해 middleware의 policy와 mechanism을 분리하고 동적으로 작동하게해
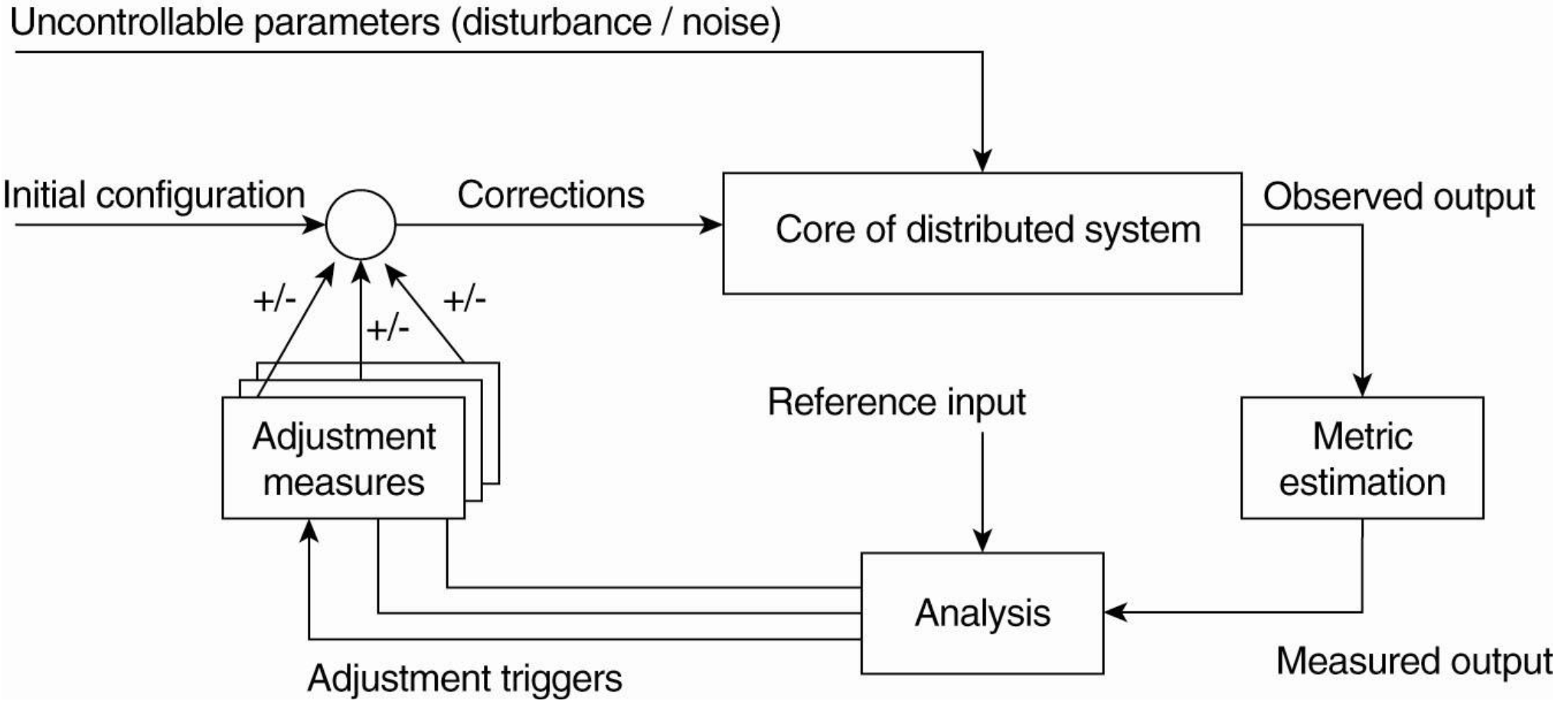
- Distributed system이 adaptive하면 좋겠다.
- Monitoring
- Analyzing measurements
- Mechanisms to influence the behavior
- 이런 것이 잘 돼야 self management한 middleware을 만들수 있을거야. 하지만 어렵겠지